




If you’ve ever typed “make the sky pink and add neon lights” into an image editor and watched the result appear like magic, you’ve brushed up against a fast-moving corner of AI: text-guided image editing. Over the last few years, models learned first to generate pictures from scratch, then to tweak existing photos based on plain-English instructions. The progress has been dazzling, but research has quietly run into a very practical bottleneck: there aren’t enough large, clean, shareable examples of real images paired with high-quality “before/after” edits and the instructions that caused them. That’s exactly the gap this paper tries to close.
The authors introduce Pico-Banana-400K, a roughly four-hundred-thousand-example dataset built from real photographs in Google’s OpenImages collection. Each example contains an original image, a natural-language editing instruction, and the edited result. The ambition here isn’t just size; it’s reliable, instruction-faithful edits that researchers can legally use and build on. Earlier resources either stayed small and hand-curated, or they grew big by stitching together synthetic content that didn’t always resemble everyday photos. Pico-Banana aims for the middle path: scale plus realism, with careful quality control.
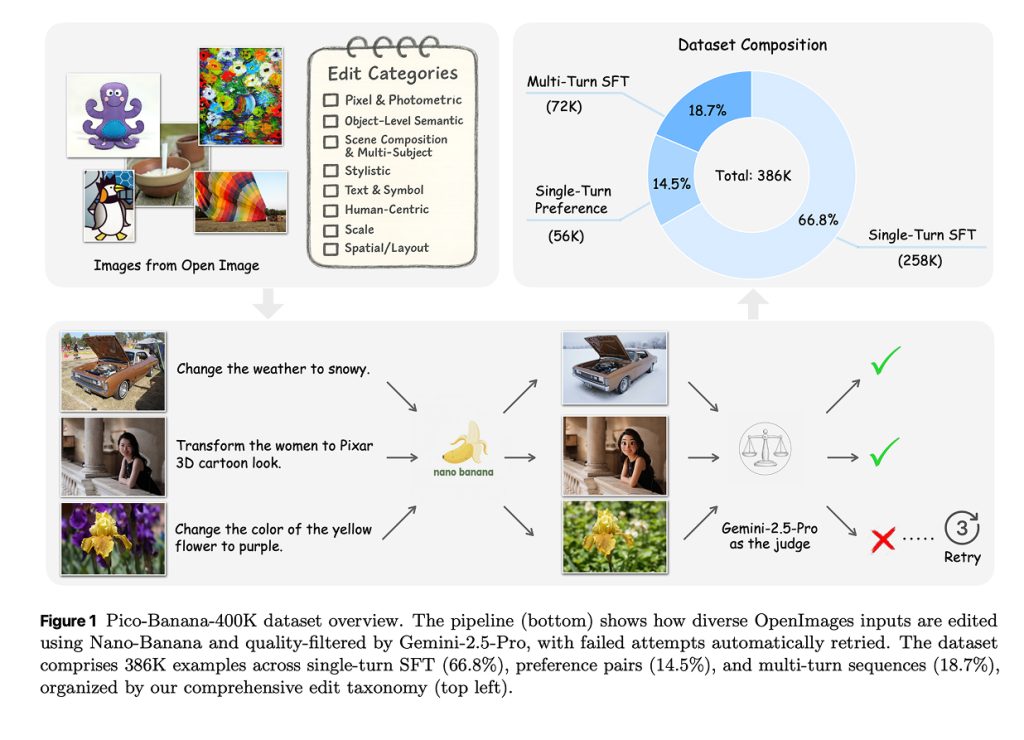
Under the hood, the pipeline runs like a little assembly line. A model writes an edit instruction for a specific photo. Another model, called Nano-Banana, performs the edit. Then a stronger multimodal judge, Gemini-2.5-Pro, scores the result on four things that matter in practice: does the image actually follow the instruction, does the edit look seamless, does the rest of the scene stay intact, and is the final picture technically sound. Only edits that clear a strict threshold make it into the main training set. I appreciate the honesty that not everything works the first time; failed attempts are kept too, paired with the successful ones, so others can train preference or reward models that learn what “good” looks like. That kind of transparency is rarer than it should be.
The team didn’t just dump random edits into a bin. They organized everything using a 35-type taxonomy that spans global color and lighting changes, object-level tweaks like “remove the cup” or “make the jacket red,” layout and background changes, stylistic remixes like “turn this photo into a sketch,” and human-centric makeovers ranging from subtle expression changes to “Pixar-style” caricatures. Each image–instruction pair is tagged with one primary edit type, which makes it much easier to ask targeted questions during model training and benchmarking.
A thoughtful touch is that every example can include two flavors of the same instruction. There’s a longer, training-oriented version that spells out context, constraints, and visual details so models have less room to misunderstand. And there’s a short, human-style version—closer to how you or I would actually type a request—that was produced by rewriting with guidance from real human annotations. In practice, this lets researchers choose between rich supervision and natural prompts without switching datasets.
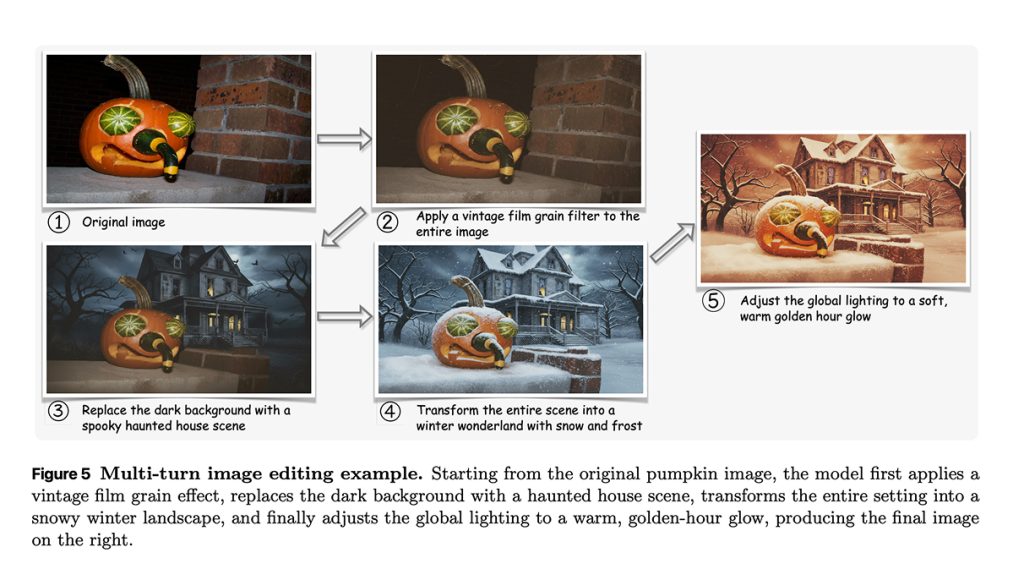
The dataset isn’t only single-shot edits, either. The authors also built multi-turn sessions, where an image gets edited two to five times in a row. Later instructions can refer back to earlier changes—“now make it blue” where “it” is the hat you just added—so models have to keep track of context and plan. That matters because real editing rarely happens in one go; people nudge, adjust, and backtrack. Teaching models to survive that messy, human loop is a step toward tools that feel more like collaborators than slot machines.
What works well?
Broad, scene-level transformations are the easy wins. Things like “apply a vintage film grain,” “shift the overall tone to warmer,” or “make it look like a comic” succeed most of the time. These edits change global texture and color statistics without demanding pixel-perfect geometry. The middle tier includes object-level semantics and backdrop swaps—removing an object, replacing a category, changing the season—which are generally robust but can still bleed into nearby regions.
The trouble zone is anything that requires precise spatial control or typography. Moving objects to specific spots, outpainting beyond the original frame, or changing fonts and translated text exposes where today’s systems still stumble: perspective consistency, boundary continuity, letterform integrity, and, for stylized portraits, keeping a person’s identity steady. It’s helpful to have these warts documented rather than hand-waved away.
Historically, the field grew along two lines. Training-free methods piggy-backed on generative models and nudged attention maps or noise schedules to steer edits without retraining. They’re clever and lightweight, but they tend to wobble on complex instructions. Finetuning-based approaches, kicked off famously by InstructPix2Pix, learn directly from instruction–before–after triplets, which unlocks more faithful edits at the cost of needing exactly the kind of data this paper provides. Pico-Banana-400K sits squarely in service of the latter: it supplies hundreds of thousands of grounded examples, clear labels, and even “good vs. bad” pairs so alignment methods like Direct Preference Optimization can be trained in the open.
There are some nuts-and-bolts details that matter for practitioners. The single-turn supervised subset is about 258,000 examples. The preference subset is roughly 56,000 paired successes and failures. The multi-turn sequences add around 72,000 examples. The judging rubric is explicit, with weights on instruction compliance, seamlessness, preservation, and technical quality, and an empirical score cutoff near 0.7. The authors even share that producing the dataset cost on the order of a hundred thousand US dollars—an unusual but welcome bit of real-world context that helps others plan their own efforts.
It’s also worth saying out loud what the paper implies between the lines. By leaning on real photos from OpenImages and publishing both images and metadata, the authors make it easier to reproduce and compare results without legal headaches. At the same time, human-centric edits—age, gender, stylized likenesses—need careful, ethically minded use. The dataset filtered where appropriate, but anyone training on it should still think through consent, bias, and how such features are deployed. Good data doesn’t remove the responsibility to use it well.
If you’re a researcher or builder, the practical upshot is simple. You get a large, license-clear corpus to train, align, and stress-test editing models. You can probe specific weaknesses—say, object relocation or text edits—because the taxonomy and success patterns point to where models break. And you can explore more realistic interaction loops with the multi-turn subset, which is where real users live.
I’ll end on a humble note. Datasets like this don’t magically solve controllability or identity preservation, and they don’t eliminate artifacts at the stroke of a prompt. But they do give the community a common, well-lit ground to stand on. With Pico-Banana-400K, it feels a bit easier to separate what’s genuinely solved from what only looks solved in cherry-picked demos—and that’s progress worth celebrating.


