




In late 2024, “brain rot” went mainstream: Oxford named it the Word of the Year to capture the worry that binging low-effort online content can dull our own attention and judgment. By mid-2025 the term was in the OED. That background matters because a new preprint borrows the phrase for AI—and, to be honest, I didn’t expect the results to be this stark.
The study—“LLMs Can Get ‘Brain Rot’!”—comes from researchers at Texas A&M, UT Austin, and Purdue. It’s a preprint (October 15, 2025), so treat it as early evidence, not settled fact. But the team did something unusually careful: they tried to isolate data quality as a causal factor in model decline. They used real Twitter/X posts to build two kinds of “junk” corpora and then continually pre-trained four instruction-tuned models on those corpora under controlled conditions (same token counts, same training recipe), comparing against clean controls.
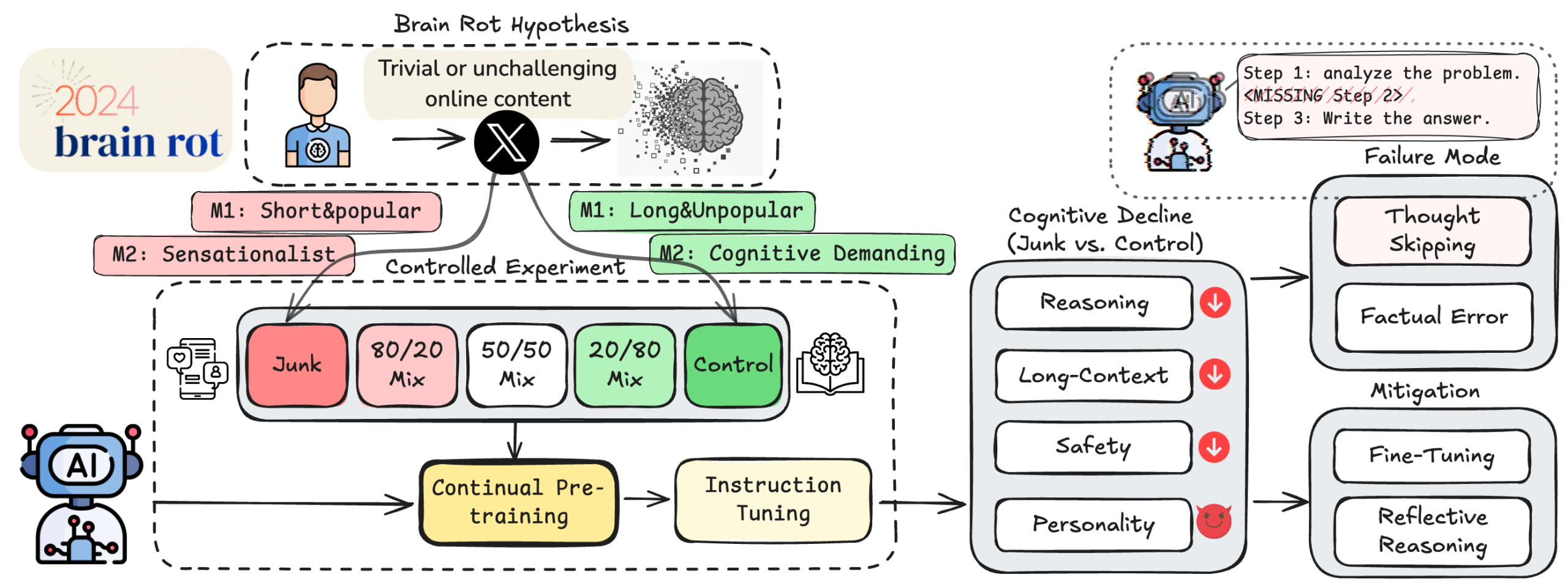
Their two “junk” dials are intuitive but different. One is engagement-driven (M1): short tweets with high popularity—likes, retweets, replies—the kind of content recommender systems are built to push. The other is semantic (M2): content labeled as sensationalist, clickbaity, or otherwise low-quality. The engagement angle is interesting on its own; it piggybacks on X’s public description of how its ranking stack optimizes for what people interact with.
What changed after feeding models this stuff? Reasoning and long-context performance dropped meaningfully, especially under the engagement-driven junk. On ARC (a grade-school science reasoning benchmark), the Llama-3-8B model with chain-of-thought prompting slid from 74.9% to 57.2% when the training mix went from 0% junk to 100%. On RULER, a suite that checks whether models can fish the right facts out of long text, one subtask (“common word extraction”) fell from 84.4 to 52.3 across the same junk gradient. Those are big moves for a single training tweak.
Safety and “personality” also shifted. The authors report higher risk scores on standard red-teaming tests after continual pre-training and, under the engagement-based junk in particular, increases on traits like narcissism or psychopathy as measured by the TRAIT questionnaire framework for LLMs. I know those words are loaded; here they’re operationalized as changes on psychometric-style multiple-choice probes, not a claim that models “feel” anything. Still, the direction of travel is uncomfortable.
The most relatable finding is the error style. When these “junk-fed” models miss, they increasingly skip the thinking. The paper shows failures where a model either answers with no rationale, lays out a plan but never executes the steps, or hops straight to a guess. If you’ve ever watched a student rush through a multi-step physics problem, you’ll recognize the pattern. The authors call this “thought-skipping,” and they tie most of the error growth to it.

They also tried to fix it. A simple “reflect and try again” loop guided by the same model didn’t help much—if your inner compass is drifting, you can’t self-correct reliably. But an external critique (they used a stronger model to point out missing steps or factual slips) reduced the thought-skipping error mode after a few rounds, though not enough to fully recover baseline scores. Post-hoc training helped somewhat too: scaling instruction-tuning data improved things, yet even 10× more instruction data didn’t fully erase the damage. That persistence makes the paper’s headline claim—lasting cognitive decline—feel less like clickbait and more like a real training-time safety concern.
A couple of examples make the dynamics concrete. Imagine a model asked a classic ARC-style control-variables question (“Why do we change only one thing in an experiment?”). A healthy chain-of-thought will list the variables, argue that changing multiple confounds the conclusion, and select “to improve reliability.” The “rotted” version might jump straight to an answer with no explanation, or it may start the plan (“1) list variables; 2) compare soaps…”) and never do step two before blurting a choice. That sounds trivial, but at scale it’s the difference between a model you trust for step-by-step help and one that confidently glosses over the parts that matter.
Why would engagement-based junk be worse than just semantically low-quality text? The authors separate tweet length (short = trivial) from popularity (non-semantic, social proof) and find they matter in different ways: popularity correlates more with reasoning damage; shortness aligns with weaker long-context handling. If you squint, it’s a mirror of human behavior online: sticky micro-posts train us to react fast and move on.
There are caveats. It’s a preprint, not peer-reviewed. The interventions are modest-scale continual pre-training runs on a handful of models; the safety and personality assessments rely on automated judges or questionnaires, which each have their own blind spots; and the “junk” definitions, while principled, are still proxies. That said, the study’s controls are careful enough to make the central message land: what we feed models after release can quietly bend their habits, and not in ways we want.
If you build or fine-tune models, the practical takeaway is uncomfortable but actionable. Treat data curation for continual pre-training as a safety problem, not just a performance problem. Track not only accuracy but how answers are produced—are steps being skipped more over time? And, if you must do open-web refreshes, bias hard toward longer, well-sourced, and non-sensational material. For context, ARC and RULER remain solid barometers for the exact capabilities this paper saw erode: reasoning under constraints and staying oriented in long contexts.
If this sounds alarmist, that’s fair. But at minimum, it’s a nudge toward routine “cognitive health checks” for deployed LLMs—simple longitudinal probes to detect when a system stops showing its work. We learned the hard way with social feeds that “what performs” and “what’s good for you” aren’t the same. Models, it seems, aren’t immune to that tension either.


